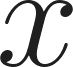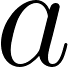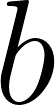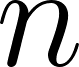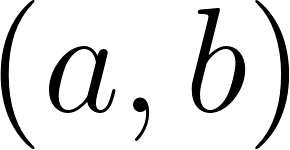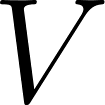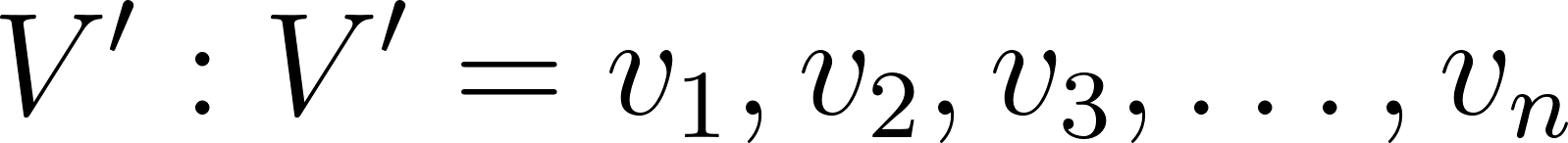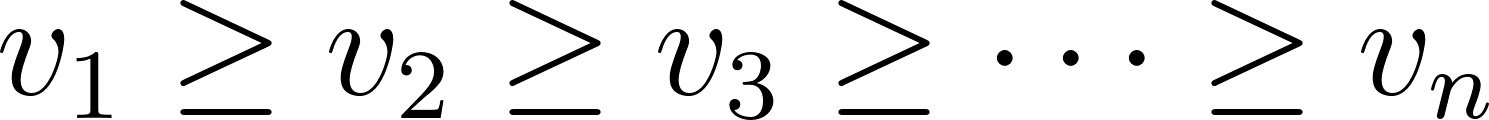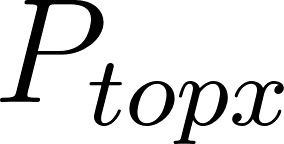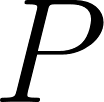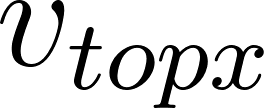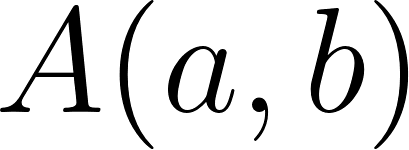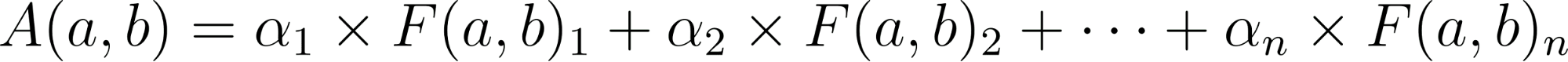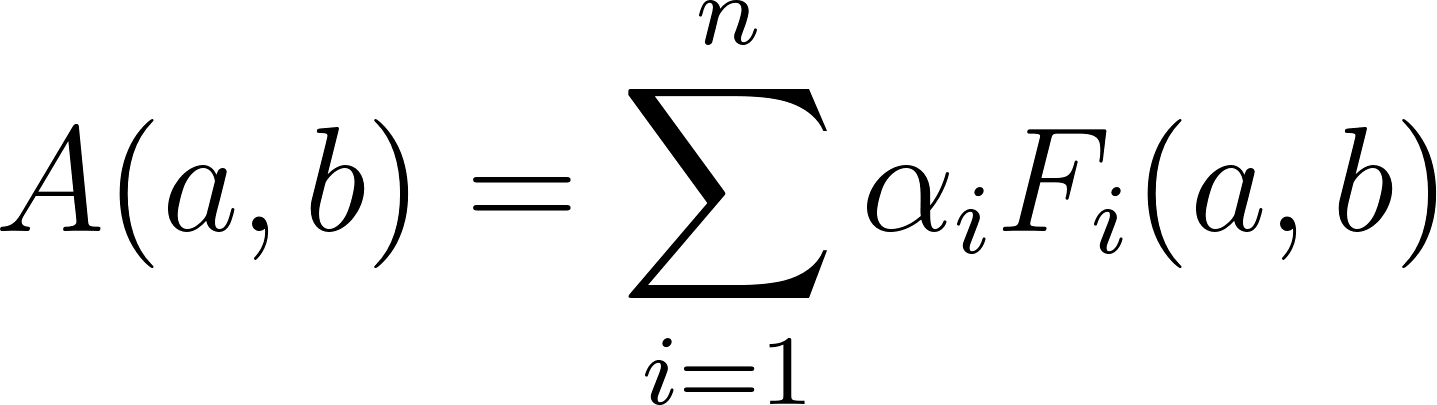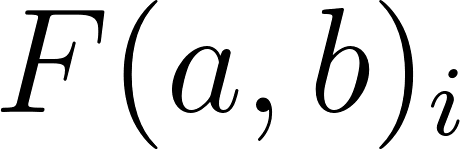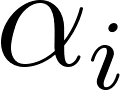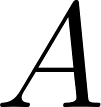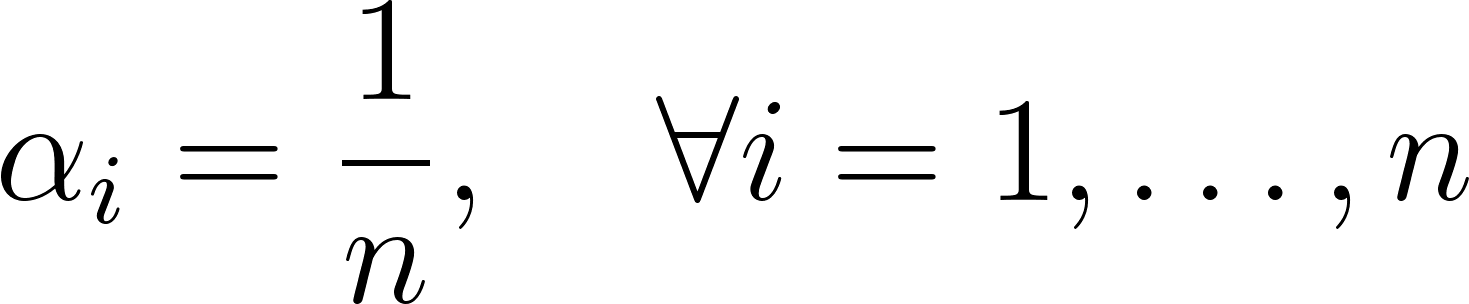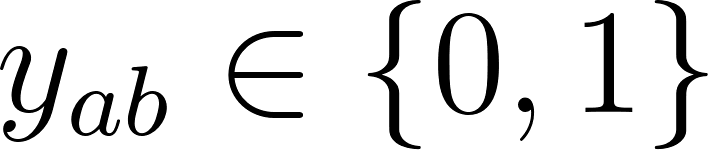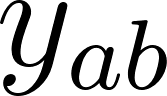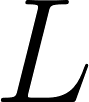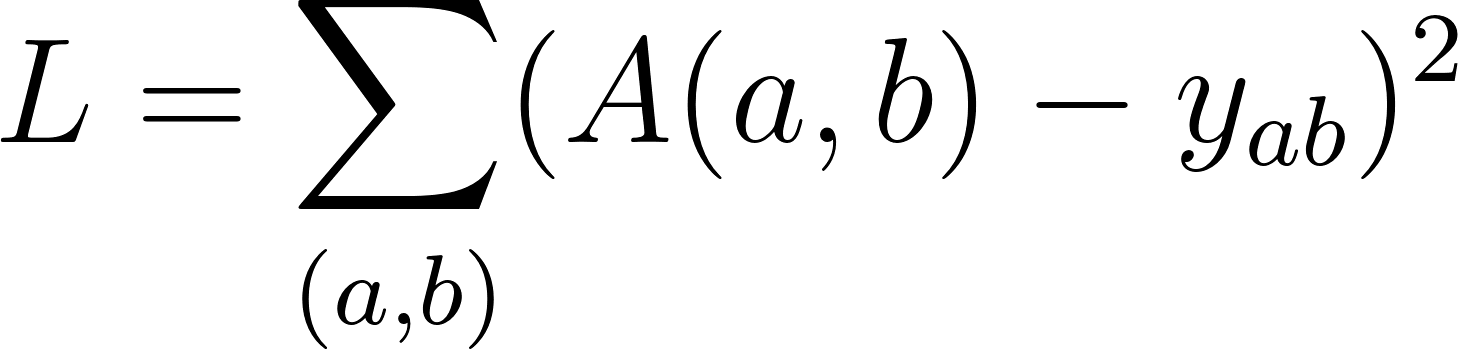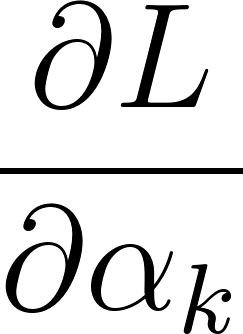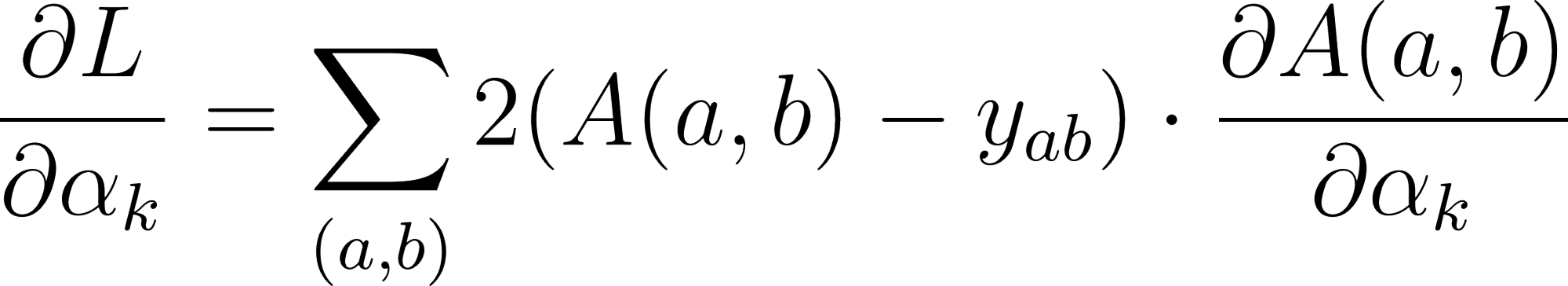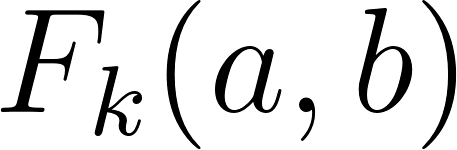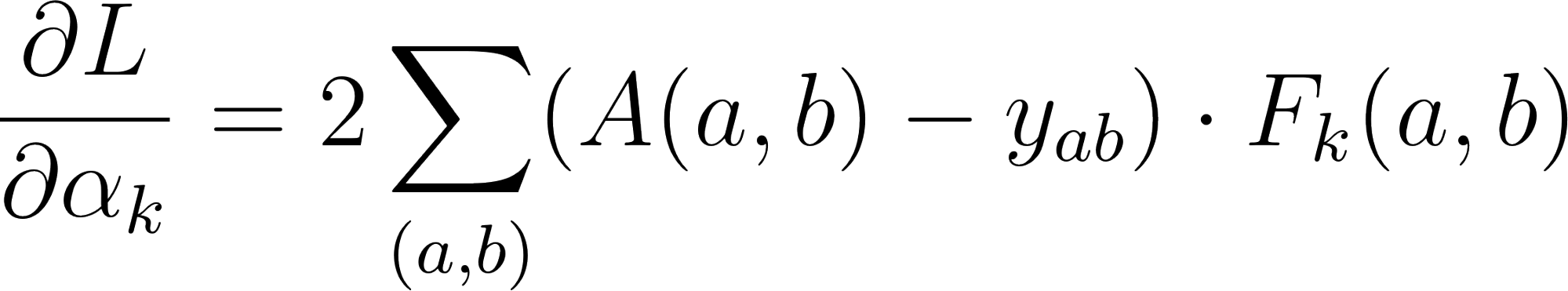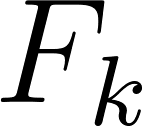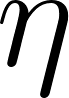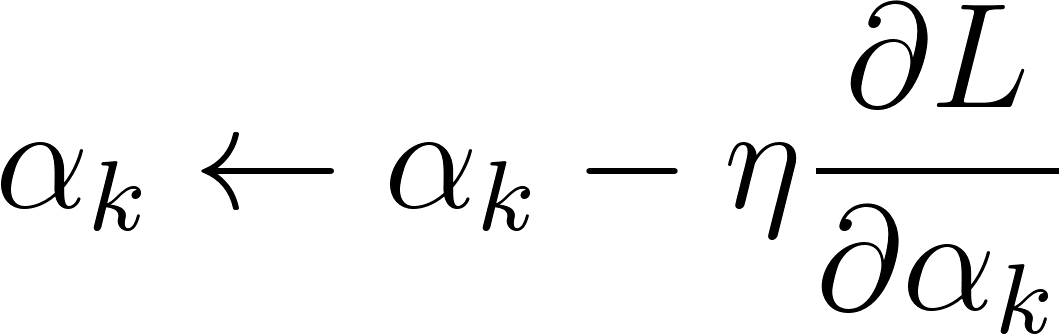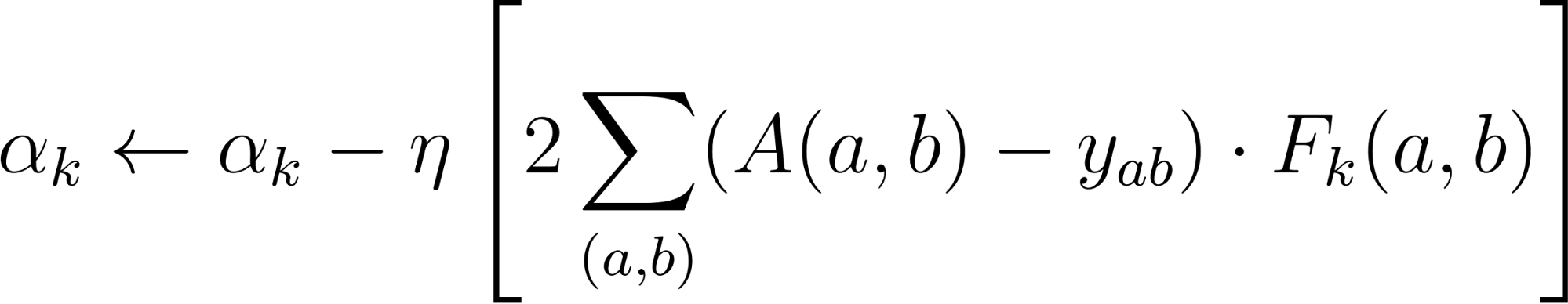8 Nov 2025
Mateo Lafalce - Blog
This work aims to find the generic mathematical-logical expression that allows any developer, regardless of the domain they are working in, to implement a matching algorithm between users with traits to measure.
Given 2 users, and , with their respective associated values, such as preferences, tastes, age, etc; Where is the user to whom recommendations are made, and is the user recommended to . We can design a function that allows us to determine which are the top users to recommend. Analytically, I can state:
Given an ordered list with pairs , where the values in are in descending order. I will call this ordered list
Where
is the resulting set containing the pairs that generate the highest values. is the set of all possible pairs. is the x-th largest value of the function after ordering them all.
That is:
Where is a function that calculates the distance that exists between a specific metric for 2 users, such as a preference for one schedule over another, or simply an absolute age difference, while is the weight given to that function.
With this formula, the score can be calculated for each pair of users, and then a top list of users with the highest scores for a given user can be obtained. This score can be plotted as a heat matrix or top ranking to visualize similarities and relationships.
We will start from the assumption that all variables taken into account for matching have the same weight at the beginning of the algorithm. Therefore:
Using backpropagation, we will update the system's weights after a certain action modifies the values of any variable under study. To do this, we will use a simple supervised prediction model.
Assuming we choose pairs with labels . is the historical data that collects our users actions and defines the success of a recommendation. It is the correct answer used to train the model. We can define a loss function , with the mean squared error such that:
The objective is to minimize . To do this, you need to know how a small change in each weight affects the total error . This is done with the partial derivative for each from 1 to .
Applying the chain rule, the derivative of the loss with respect to a weight is:
Given that , the derivative of with respect to is simply .
Therefore, the gradient for the weight is:
For each weight , its gradient is the sum (over all training examples) of the (prediction error) multiplied by (the value of the corresponding feature ).
Once we have the gradient for each weight, we update them all simultaneously using the learning rate .
For each from to :
Substituting the gradient formula:
This process (calculating predictions, calculating the gradient for each , and updating each ) is repeated several times until the weights converge and the error is minimized.
You can find this algorithm ready to be implemented in any domain that requires a matching system here.
This blog is open source. See an error? Go ahead and propose a change.