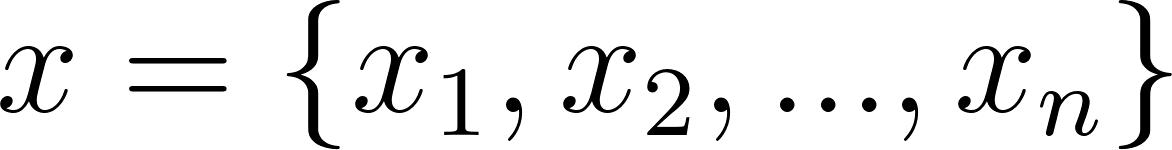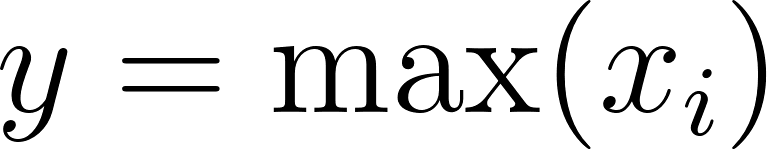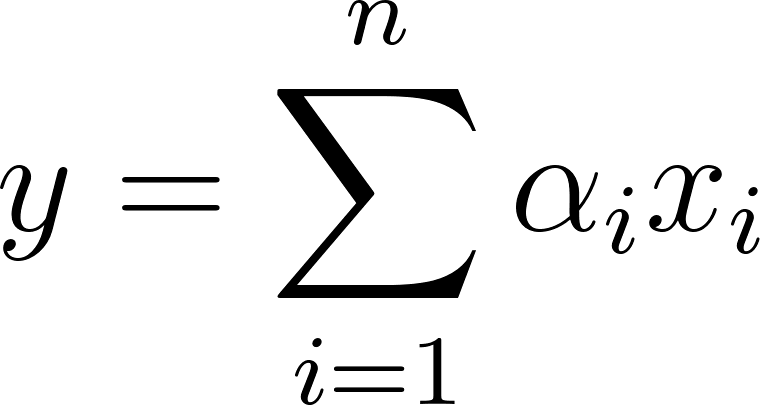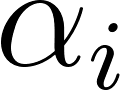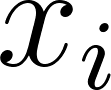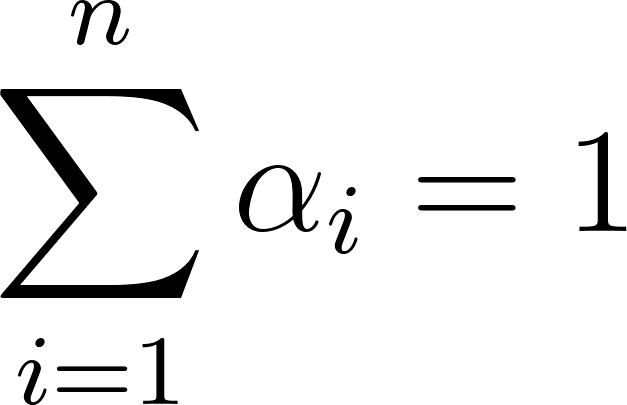15 Jan 2026
Mateo Lafalce - Blog
Deep learning architectures frequently encounter the challenge of downsampling high dimensional data while attempting to retain the most critical information for the final prediction.
Max Pooling has served as the standard solution for this task due to its computational efficiency and ability to provide translation invariance. In a traditional Max Pooling operation over a specific window of input features , the network performs a hard selection mechanism defined formally as .
This approach effectively captures the most prominent feature in a local region, such as a sharp edge in an image or a dominant keyword in a sentence, by allowing only the strongest signal to pass through to the next layer.
However, this rigid selection process inherently suffers from information loss because it completely discards all non maximum values regardless of their potential contextual value.
Attention Pooling addresses this limitation by replacing the hard selection rule with a soft, learnable weighted summation. Instead of arbitrarily keeping only the highest value, the network calculates an attention score that represents the relevance of each feature to the specific task at hand.
This process is mathematically expressed as , where is the attention weight assigned to feature . These weights are typically normalized, often using a Softmax function, to ensure that the condition is met.
This mechanism allows the model to aggregate information from multiple relevant features simultaneously, creating a comprehensive summary of the input region rather than a single data point.
The determination of whether Attention Pooling is superior to traditional Max Pooling relies on the trade off between semantic expressiveness and computational cost. Attention Pooling is generally considered better for complex tasks because it is context-aware and preserves gradients for all features, allowing the network to learn more subtle relationships within the data.
While Max Pooling remains a useful tool for basic dimensionality reduction in the early layers of a Convolutional Neural Network due to its speed, Attention Pooling offers a significant advantage in deeper layers or sequence modeling.
By allowing the network to focus dynamically on what matters most rather than simply what is loudest, Attention Pooling provides a more nuanced and accurate representation of complex data structures.
This blog is open source. See an error? Go ahead and propose a change.