17 Jan 2026
Mateo Lafalce - Blog
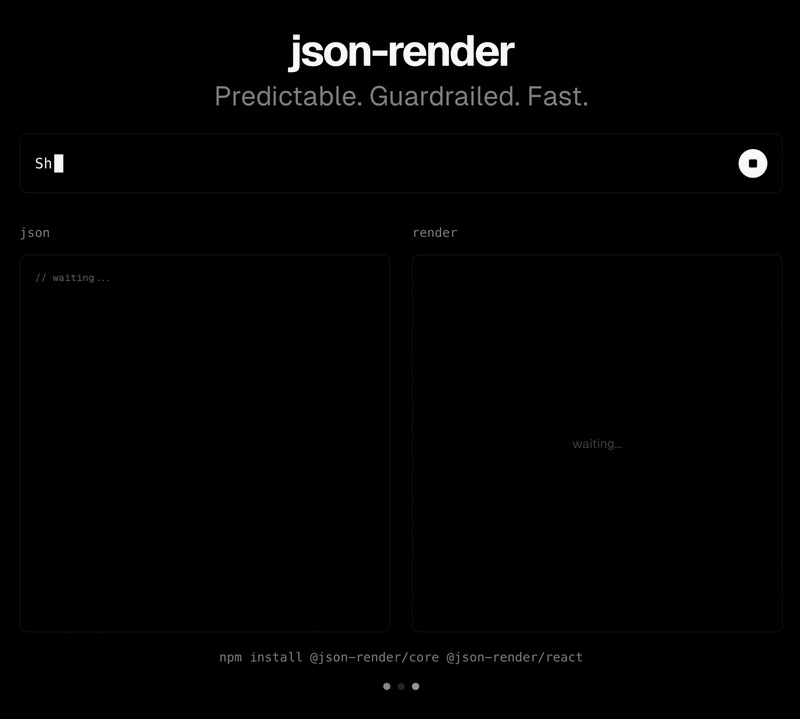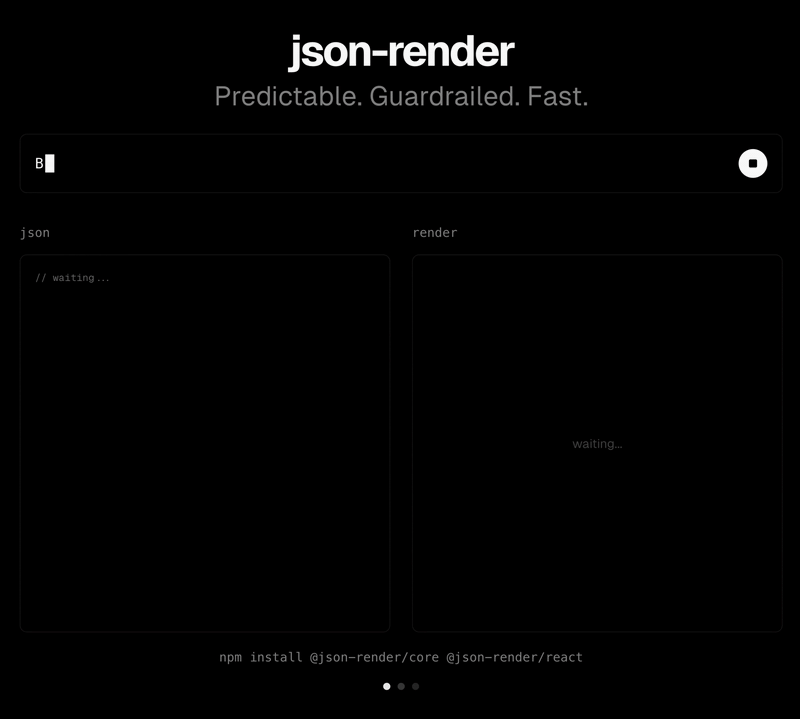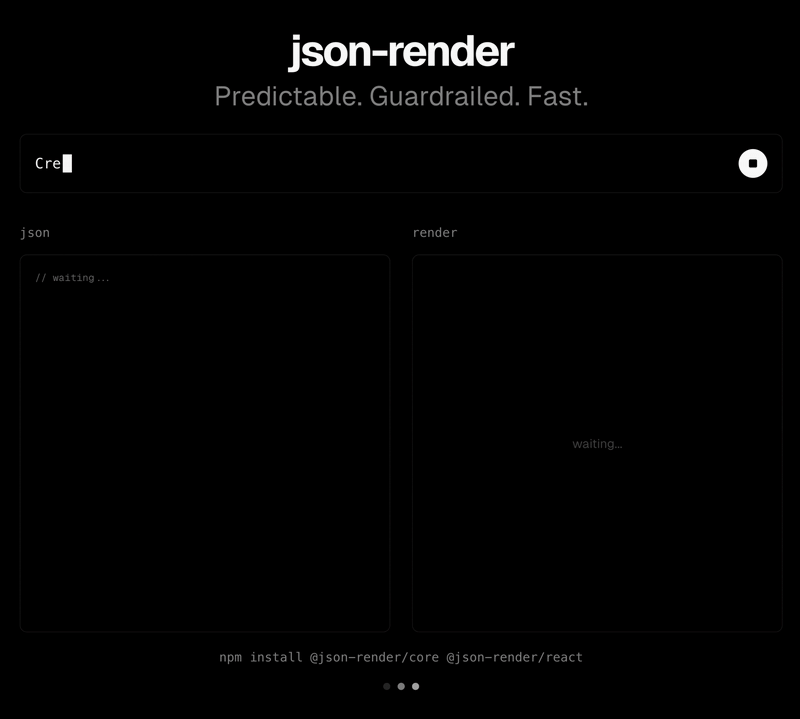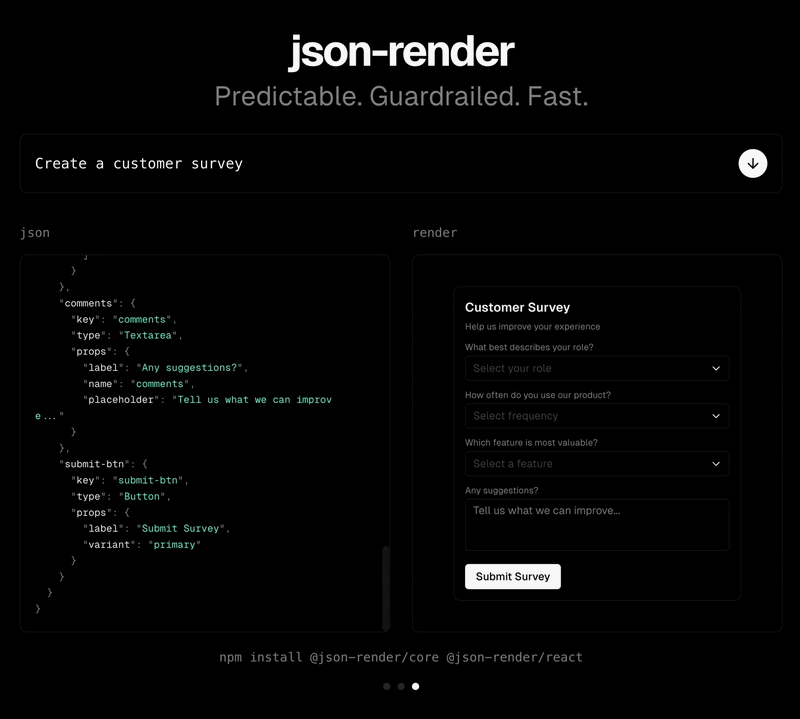
Vercel's json-render is an elegant solution for dynamically generating UIs using generative AI. The tool leverages Claude Opus 4.5 to produce structured JSON output that can be rendered as interactive interfaces. While exploring this excellent project, I discovered an opportunity to significantly optimize costs through an alternative output format.
The project uses JSONL as the output format, which is human-readable and easy to work with. However, JSONL's verbosity presents an optimization opportunity, especially when output tokens cost 3x more than input tokens with Claude Opus 4.5.
Source: Claude Docs (17/01/2026)
The Hypothesis
I hypothesized that switching from JSONL to TOON would dramatically reduce costs, even after accounting for the additional context needed to explain the TOON format to the LLM.
The math was compelling: if we could reduce output tokens significantly, the savings would more than offset the small increase in input tokens required to explain TOON formatting.
The Benchmark
To validate this hypothesis, I created a comprehensive benchmark comparing two implementations:
I tested both implementations across 10 different UI generation prompts, measuring three critical metrics:
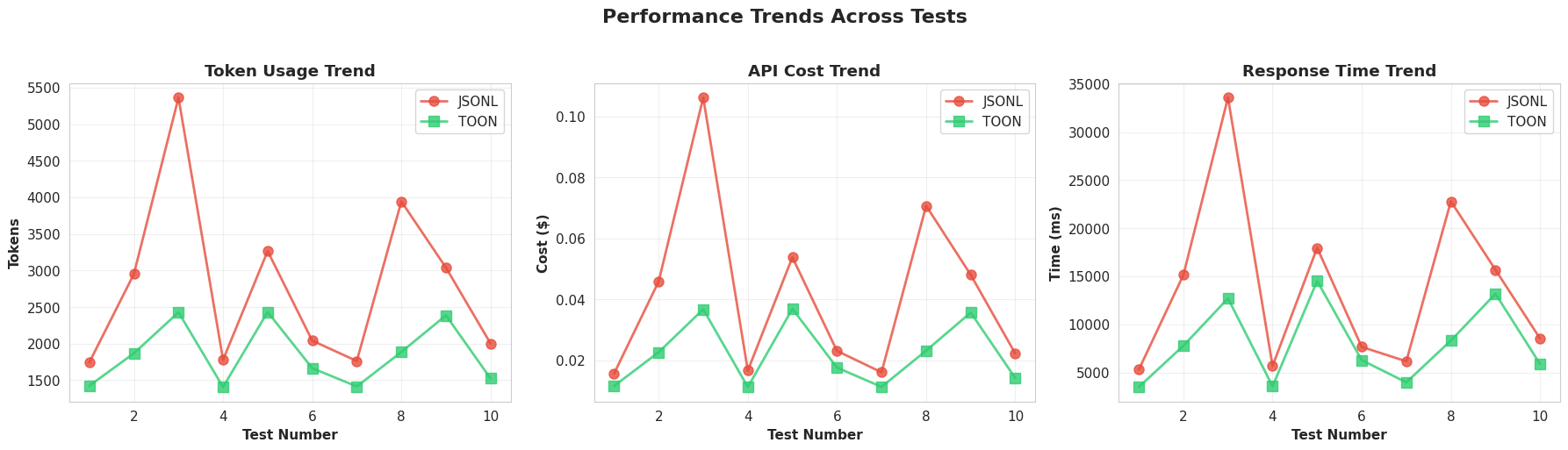
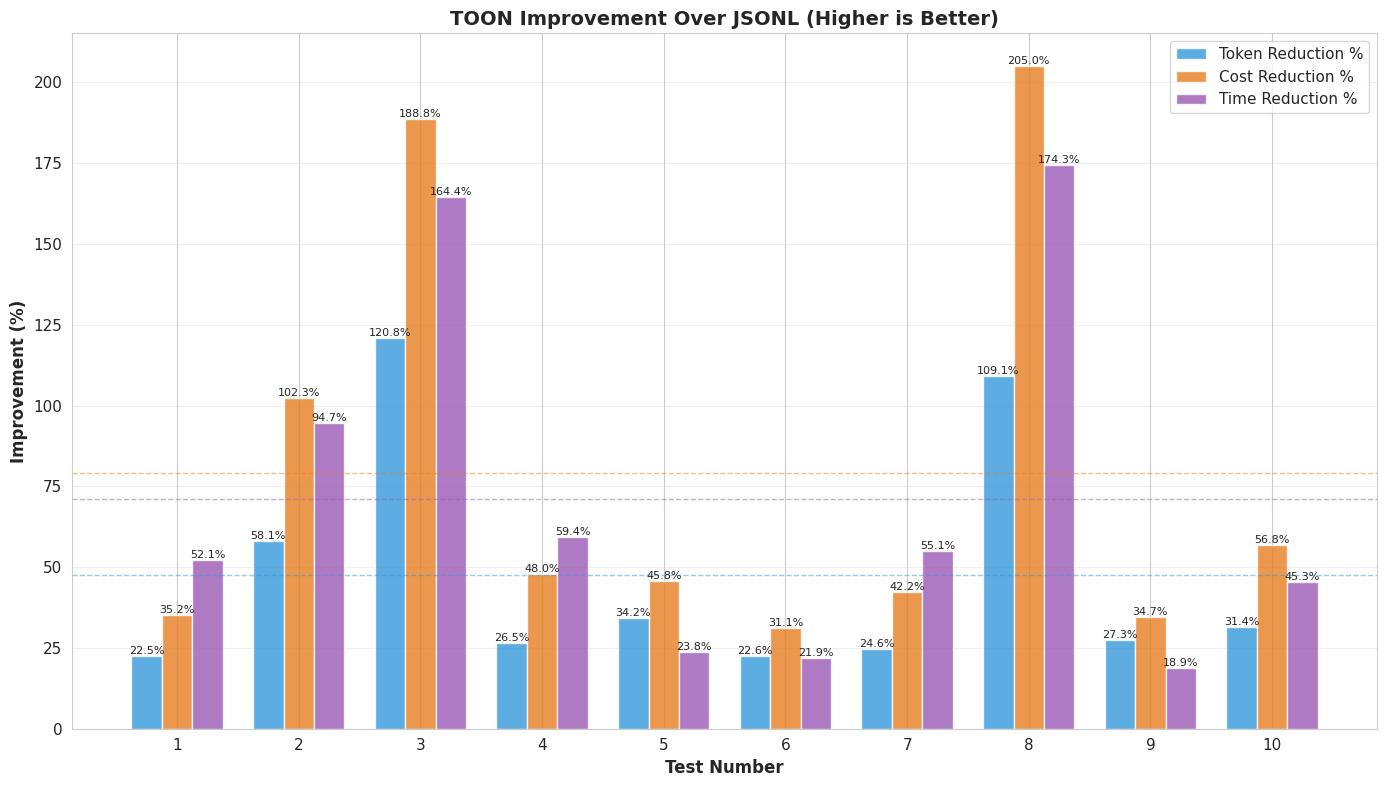
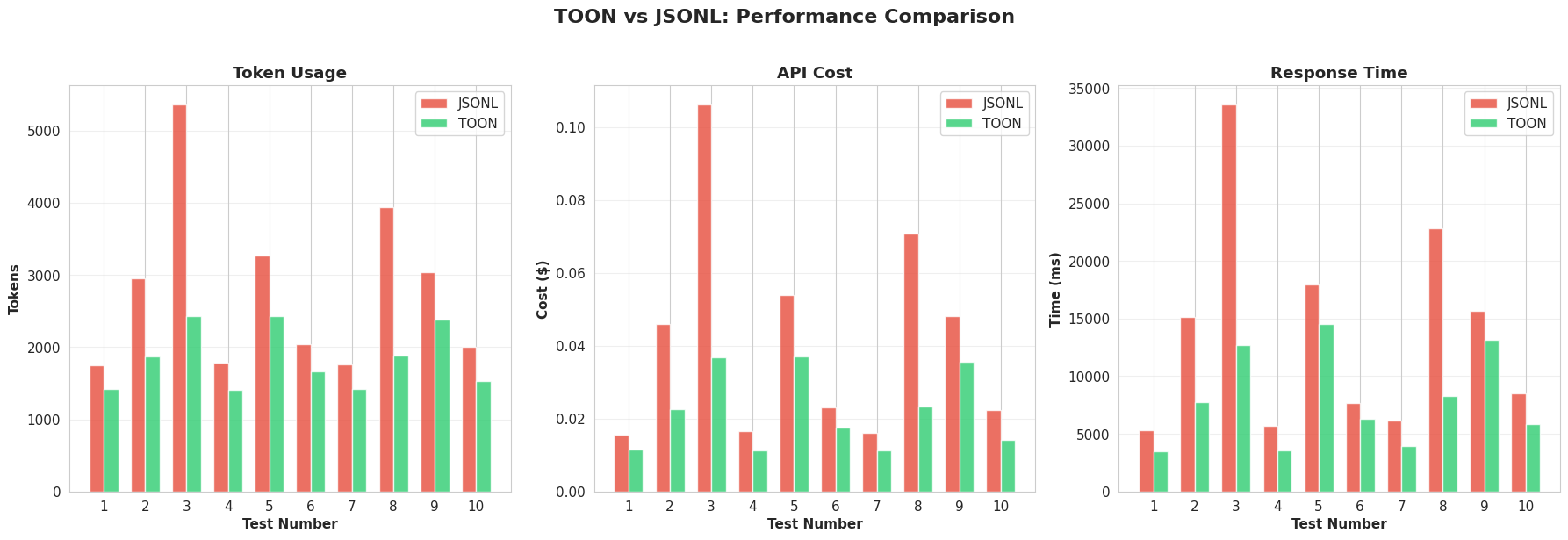
The Results
The results exceeded my expectations:
Token Efficiency:
Cost Savings
Performance
Trade-off
There's one important limitation: TOON doesn't support streaming in chunks like JSONL does, so the entire response must be generated before decoding, which means no "hot loading" of partial results :(
The Broader Lesson
This benchmark reveals an important principle for working with LLMs: optimize for compact output formats when output tokens cost more than input tokens.
Many developers focus on reducing input context, but when output tokens are 3x more expensive, the real opportunity lies in minimizing what the LLM generates. TOON is just one example. The key insight is to think critically about your output format:
Conclusion
By exploring TOON as an alternative to JSONL, this optimization achieved:
This exploration of json-render demonstrates a broader principle for optimizing any LLM application that generates structured output. When output tokens are expensive, compact formats can provide substantial benefits for building cost-effective AI applications at scale. I'm grateful to Vercel for creating such an excellent project to experiment with!
This blog is open source. See an error? Go ahead and propose a change.