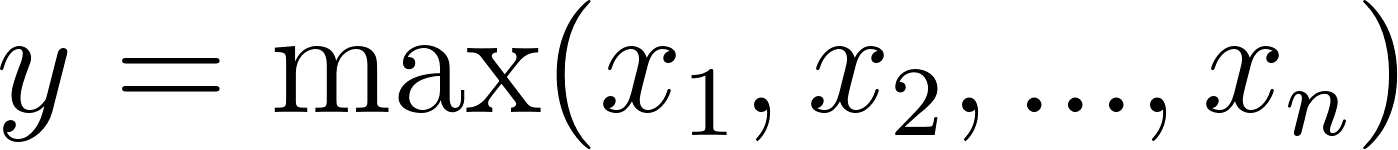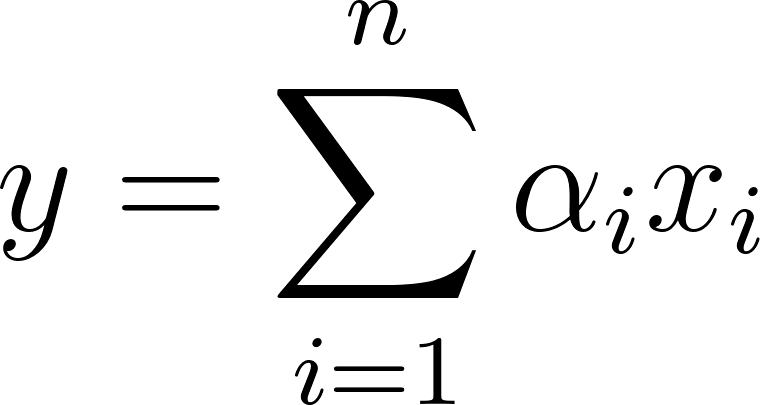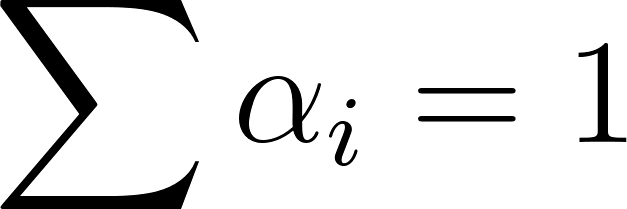13 Jan 2026
Mateo Lafalce - Blog
The primary reason researchers generally avoid placing attention mechanisms and max pooling layers in immediate succession lies in their philosophically opposing approaches to information processing.
While max pooling acts as a hard selection filter that permanently discards information, attention mechanisms serve as soft weighting systems designed to preserve context.
Combining them sequentially often results in a redundant architecture where the nuanced calculations of the attention layer are immediately nullified by the brute force nature of the pooling layer.
From a mathematical perspective, max pooling is a fixed and non-learnable operation defined as . It operates on the assumption that only the single highest activation in a local region contains value, effectively setting the importance of all other features to zero.
In contrast, an attention mechanism is a learnable operation that assigns a continuous importance score, denoted as , to every feature. The output is a weighted sum represented by , where the weights usually sum to one such that . If a network expends computational resources to calculate specific values for every feature, only to have a subsequent max pooling layer select a single and discard the rest, the network has effectively wasted the gradient computation for every non-maximal feature.
This conflict extends to the flow of gradients during backpropagation. Max pooling creates sparse gradients because the derivative of the max function is for the maximum value and for all other values. This means that during training, the signal only creates updates for the "winning" neuron.
Attention mechanisms are designed to utilize dense gradients, allowing the error signal to flow back to all inputs simultaneously proportional to their attention weights. Placing max pooling after attention creates a bottleneck that severs this dense gradient flow, preventing the model from learning complex relationships among the non-maximal features.
Furthermore, these two operations handle spatial resolution in contradictory ways. Attention mechanisms, particularly self-attention, thrive on high resolution spatial data to determine global relationships between distant pixels or features.
Max pooling is explicitly designed to reduce spatial resolution and induce translation invariance. By downsampling the feature map immediately after or before an attention block, the architecture loses the precise spatial coordinates necessary for the attention mechanism to generate an accurate heat map of relevant features.
There are rare exceptions where these concepts merge, such as in the Convolutional Block Attention Module (CBAM), but the application is distinct. In these cases, max pooling is not used as a subsequent filter but rather as an input descriptor to help calculate the attention weights themselves.
Outside of such specific use cases, modern deep learning architectures favor attention over pooling because attention learns which features are important through the variable , whereas max pooling assumes importance based solely on magnitude. Consequently, replacing pooling with strided convolutions or pure attention layers allows the network to retain a richer, more context-aware representation of the data.
This blog is open source. See an error? Go ahead and propose a change.