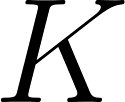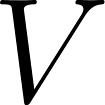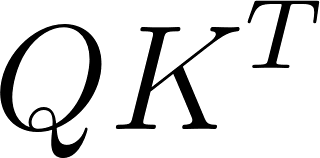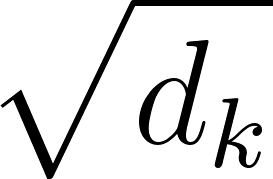12 Jan 2026
Mateo Lafalce - Blog
The Attention Mechanism represents a pivotal shift from passive data processing to active cognitive modeling. Much like human vision, which blurs the periphery to focus sharply on a specific object, the attention mechanism allows a neural network to dynamically assign importance to different parts of an input signal.
Rather than processing a 10.000 pixel image or a 50 word sentence with uniform weight, the model learns to isolate the signal from the noise, prioritizing the data points that are most relevant to the immediate task.
At its mathematical core, this process is effectively a sophisticated retrieval system based on vector similarity. The mechanism operates using three distinct vectors derived from the input data: the Query (), the Key (), and the Value ().
You can visualize this as a database lookup where the model asks a specific question (the Query) and compares it against various attributes (the Keys) to retrieve the appropriate content (the Values).
To determine relevance, the model calculates the dot product between the Query and the Key, denoted as . A high dot product indicates high similarity or alignment between what the model is looking for and what the input feature offers.
To convert these raw similarity scores into usable probabilities, the system applies a Softmax function. This normalization ensures that the attention weights sum to 1, effectively creating a percentage based distribution of focus.
The final output is then computed as a weighted sum of the Values, where the most relevant information is amplified, and irrelevant data is suppressed. This operation is formally defined by the equation
, where acts as a scaling factor to prevent the gradients from vanishing during training.
While originally designed for Natural Language Processing to solve the bottleneck problem in translation, where long sentences lost context when compressed into fixed vectors, this logic has been seamlessly adapted to Convolutional Neural Networks (CNNs).
In the visual domain, attention does not just look at sequence order but applies Spatial Attention and Channel Attention.
By integrating this mechanism, deep learning models have evolved from static systems into dynamic architectures capable of understanding context, nuance, and global relationships within data.
This blog is open source. See an error? Go ahead and propose a change.