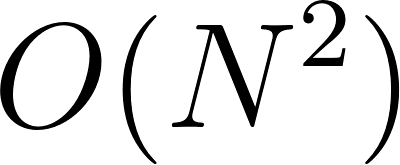16 Jan 2026
Mateo Lafalce - Blog
Large Language Models have revolutionized ai, yet they face fundamental barriers that prevent indefinite scaling. The primary technical bottleneck resides in the architecture itself.
This specific limitation is rooted in the attention mechanism which exhibits quadratic complexity. When a model processes a sequence of length , it calculates relationships between every pair of tokens to understand context.
Mathematically, this operation requires the computation of an matrix where each token attends to every other token. Consequently, the computational complexity follows the function .
This implies that doubling the input length results in four times the memory and processing requirements, while increasing the input by a factor of ten increases the computational cost by a factor of one hundred.
This quadratic growth makes processing very long documents exponentially expensive and technically difficult without significant architectural optimizations.
Beyond this algorithmic constraint, external physical and data limitations impose hard boundaries on growth. The first hurdle is data scarcity.
Models require vast amounts of unique human text for training, and developers are approaching the limit of available superior quality public data. Supplementing this with synthetic data risks model collapse, a phenomenon where the output becomes repetitive and degrades in variance.
Furthermore, the energy and hardware demands follow a path of diminishing returns known as scaling laws. These laws suggest that increasing model parameters yields smaller marginal improvements in intelligence while exponentially increasing financial and energy costs.
These combined factors of quadratic algorithmic complexity, finite data resources, and physical hardware limits suggest that the strategy of simply increasing model size is approaching a definitive plateau.
This blog is open source. See an error? Go ahead and propose a change.