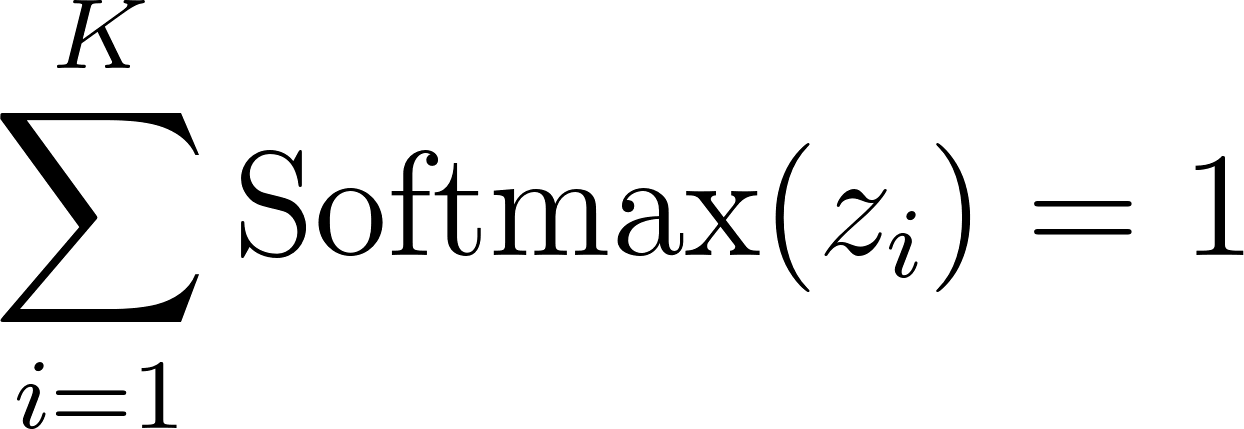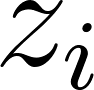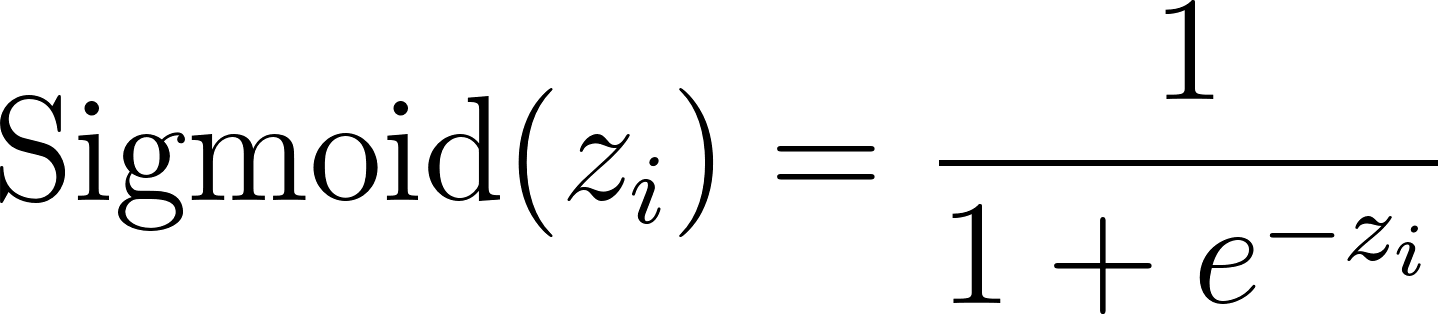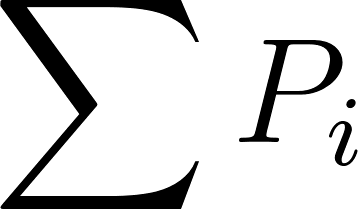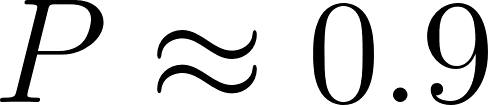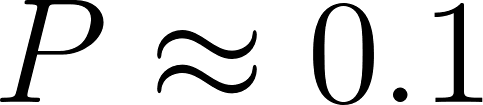3 Jan 2026
Mateo Lafalce - Blog
Why not just use Softmax for everything instead of Sigmoid?
The answer lies in the fundamental difference between competition and independence.
The core distinction is how these functions treat the output space . Softmax enforces competition. It normalizes the output vector such that the sum of all probabilities equals exactly 1.
Because of this constraint, if the probability of class increases, the probability of class must decrease mathematically. They are fighting for a slice of the same pie.
Sigmoid allows independence. Sigmoid squashes each individual output between 0 and 1 independently of the others.
Here, can be greater than 1. The probability of class has no mathematical impact on class .
To visualize this, imagine the output layer of your network:
If you use Softmax for a multi-label problem, you confuse the network.
If the network detects a Dog , Softmax will force the probability of Grass to drop to satisfy the summation constraint. You are effectively penalizing the model for being correct about the second object.
Rule of Thumb:
This blog is open source. See an error? Go ahead and propose a change.